


Karbonfotavtrykket til datasentre, som tilbyr cloud computing-tjenester, kan variere sterkt.Kreditt: China Feature/Future Publishing/Getty
Ettersom maskinlæringseksperimenter blir mer sofistikerte, eksploderer karbonavtrykket deres. Nå har forskere beregnet karbonkostnadene ved å trene en rekke modeller i skydatasentre på forskjellige steder.1. Funnene deres kan hjelpe forskere med å redusere utslipp skapt av arbeid som er avhengig av kunstig intelligens (AI).
Teamet fant markante forskjeller i utslipp mellom geografiske steder. For det samme AI-eksperimentet produserte «de mest effektive regionene omtrent en tredjedel av de minst effektive utslippene», sier Jesse Dodge, en maskinlæringsforsker ved Allen Institute for AI i Seattle, Washington, som ledet studien. .
Til nå har det ikke vært gode verktøy for å måle utslipp produsert av skybasert AI, sier Priya Donti, en maskinlæringsforsker ved Carnegie Mellon University i Pittsburgh, Pennsylvania, og medgründer fra Climate Change AI-gruppen.
«Dette er flott arbeid av gode forfattere og bidrar til en viktig dialog om hvordan maskinlæringsarbeidsmengder kan håndteres for å redusere utslippene deres,» sier hun.
Plassering er viktig
Dodge og hans samarbeidspartnere, som inkluderte Microsoft-forskere, overvåket strømforbruket mens de trente 11 vanlige AI-modeller, alt fra typer språkmodeller som understøtter Google Translate til synsalgoritmer som automatisk merker bilder. De kombinerte disse dataene med estimater for endrede utslipp fra strømnettene som driver 16 Microsoft Azure-skyservere over tid, for å beregne treningsstrømforbruk på en rekke steder.
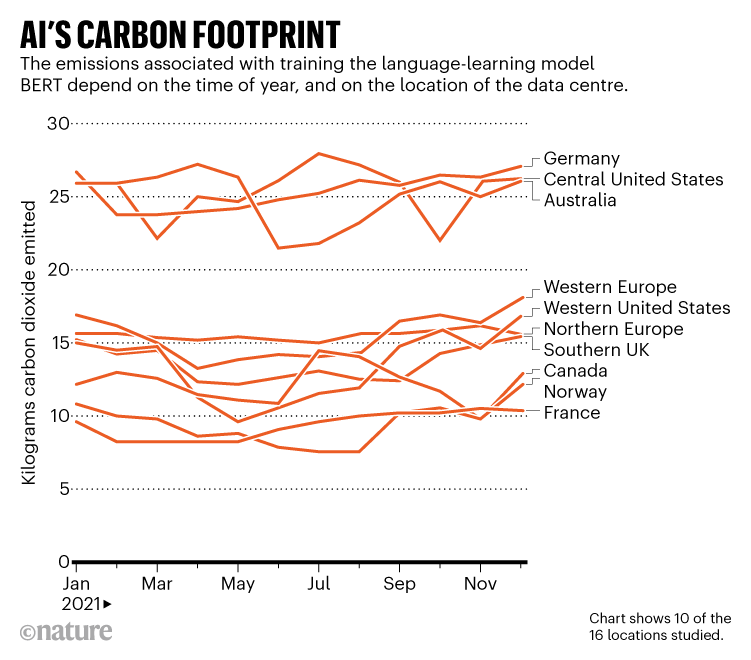
Kilde: Ref. 1
Anlegg på forskjellige steder har ulike karbonavtrykk på grunn av global variasjon i energikilder, samt svingninger i etterspørselen. Teamet fant ut at opplæring av BERT, en vanlig maskinlæringsspråkmodell, i sentrale amerikanske eller tyske datasentre slapp ut 22 til 28 kilo karbondioksid, avhengig av tidsperioden på året. Dette var mer enn det dobbelte av utslippene generert av det samme eksperimentet i Norge, som henter mesteparten av sin elektrisitet fra vannkraft, eller Frankrike, som hovedsakelig er avhengig av kjernekraft (se «Karbonfotavtrykket til AI»).
Tidspunktet på døgnet eksperimentene finner sted er også viktig. For eksempel førte trening av AI i Washington om natten, når statens elektrisitet utelukkende kommer fra vannkraft, til lavere utslipp enn på dagtid, når strømmen også kommer fra kraftverk i gassen, sier Dodge, som presenterte resultatene. på Association for Computing Machinery-konferansen om rettferdighet, ansvarlighet og åpenhet i Seoul forrige måned.
AI-modellene varierte også voldsomt i showene sine. DenseNet Image Classifier opprettet den samme CO2 viser som å lade en mobiltelefon, mens man trener en mellomstor versjon av en språkmodell kjent som en Transformer (som er mye mindre enn den populære GPT-3-språkmodellen, laget av selskapet OpenAI-forskningsanlegget i San Francisco, California) produserer ca. de samme utslippene som en typisk amerikansk husholdning genererer i løpet av et år. I tillegg fullførte teamet bare 13 % av transformatoropplæringsprosessen; full trening ville gi utslipp «i størrelsesorden for å brenne en hel jernbanevogn full av kull,» sier Dodge.
Utslippstallene er også undervurdert, legger han til, fordi de ikke inkluderer faktorer som energien som brukes til datasenteroverhead eller utslippene som trengs for å lage nødvendig maskinvare. Ideelt sett ville tallene også ha inkludert feilsøyler for å ta høyde for store underliggende usikkerheter i et nettverks utslipp til enhver tid, sier Donti.
Grønnere valg
Der andre faktorer er like, håper Dodge at studien kan hjelpe forskere med å bestemme hvilket datasenter som skal brukes til eksperimenter med sikte på å minimere utslipp. «Denne beslutningen, viser det seg, er en av de mest virkningsfulle tingene noen kan gjøre» i disiplinen, sier han. Takket være dette arbeidet gjør Microsoft nå informasjon om strømforbruket til maskinvaren tilgjengelig for forskere som bruker Azure-tjenesten.
Chris Preist ved University of Bristol, Storbritannia, som studerer virkningen av digital teknologi på miljømessig bærekraft, sier at ansvaret for å redusere utslipp bør ligge hos skyleverandøren i stedet for forskeren. Leverandører kunne sørge for at de laveste karbondatasentrene til enhver tid brukes mest, sier han. De kan også ta i bruk fleksible strategier som lar maskinlæringssykluser starte og stoppe til tider som reduserer utslipp, legger Donti til.
Dodge sier at teknologiselskapene som utfører de største eksperimentene bør ta det største ansvaret for åpenhet rundt utslipp og forsøke å minimere eller utligne dem. Maskinlæring er ikke alltid dårlig for miljøet, påpeker han. Dette kan bidra til å designe effektive materialer, modellere klimaet og spore avskoging og truede arter. Ikke desto mindre er det økende karbonavtrykket til AI i ferd med å bli en stor kilde til bekymring for noen forskere. Selv om noen forskningsgrupper jobber med å spore karbonutslipp, har åpenhet «ennå ikke nådd en fellesskapsstandard,» sier Dodge.
«Dette arbeidet har vært fokusert på å bare prøve å få åpenhet om dette temaet, fordi det er sårt mangelfullt akkurat nå,» sier han.

«Popkulturfan. Kaffeekspert. Baconnerd. Opprørende ydmyk formidler. Vennlig spiller.»




